概要
東方妖々夢のゲーム画面の左下には3つの数字がある.
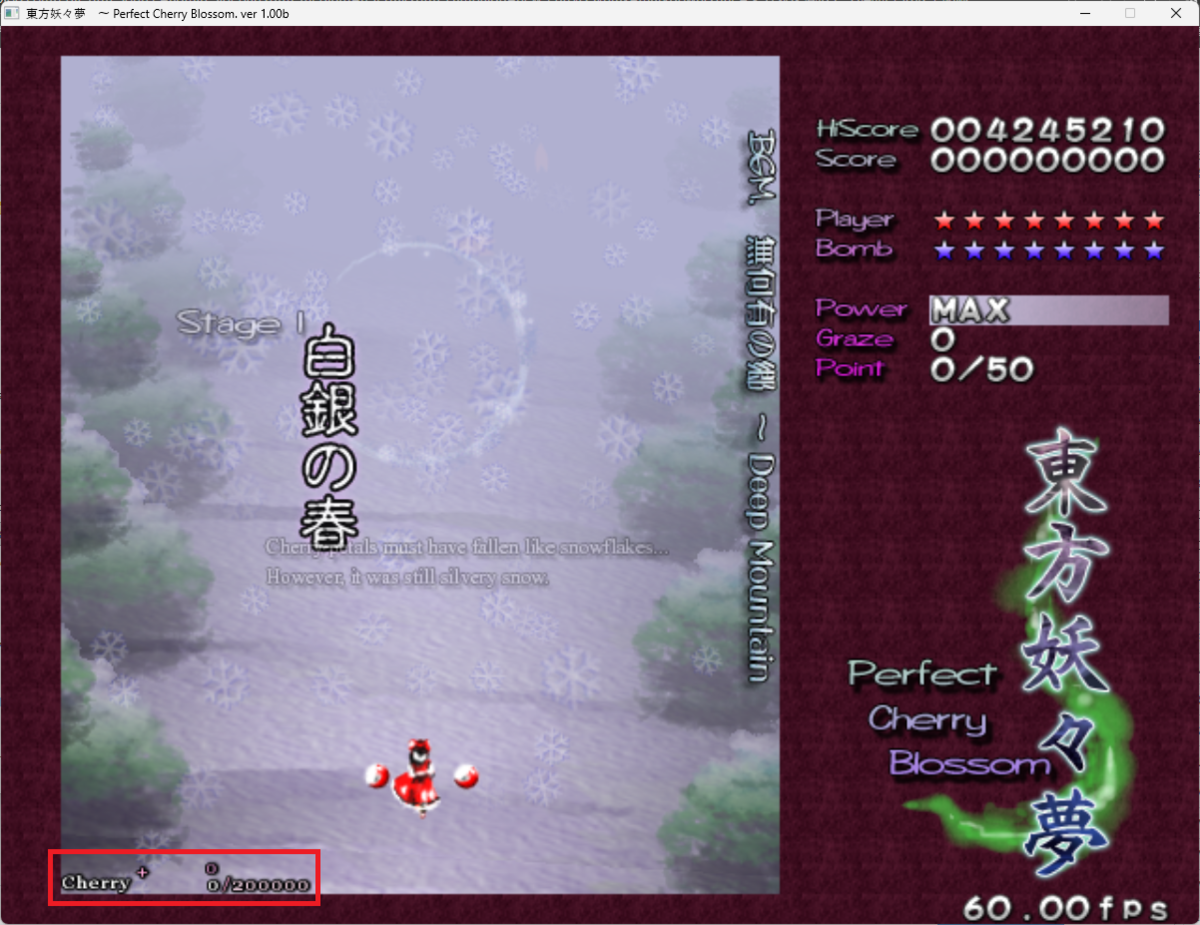
この数字は主にスコアアタックで重要になるが,うまく使うと通常クリアやノーボム(以下NB)でも役に立つ.
私はこのゲームのスコアアタックを行っているのだが,ポイント毎にどの程度増えたのかを認識しつつプレイしている.
とはいえ毎回覚えているわけでもなく,できれば記録してどこがダメなのかを把握して自分の弱点部分の練習を行いたい状況は多い.
一応東方作品にはリプレイ機能を搭載しているので,リプレイファイルを保存して振り返ればデータを手動で取ることは一応可能である.
しかしこれは結構手間であり,自動記録を行うツールが欲しいと思っていたのだ.
現状そのようなツールはなく,じゃあ自分で作ってみるか,となったわけである.
東方妖々夢の左下の解説
簡単に妖々夢の左下の三つの数字について説明しておく.

まず上段について,ここが50,000に到達すると森羅結界(以下結界)が発動する.この結界がスコアアタックにおいては非常に重要になる.
次に下段右,これは下段左の数字の上限を表している.この数字は結界中と結界終了時にのみ増やすことができる.正式名称はないが,一般的には桜分母と呼ばれる.
最後に下段左,これは現在の点アイテムの最大点を表している.東方妖々夢では点アイテムを回収した場所が画面上部であるほどこの数字に近づくことになる.ここも正式名称はないが,桜分子と呼ばれる.
まとめると,特に下段の二つの数字をできるだけ高く保つ必要がある,ということになる.
そのため結界中にどれだけ伸びたのかを記録し,他プレイヤーと比べてどうなのかの調査につなげるのが目的となる.
数字認識の方針
何を使って予測するのか
今回は深層学習を使って文字認識を行う.
文字認識についてはMNIST等の手書き文字の認識を行うサンプルが多く公開されているため,似たようなことは可能と考えられる.
対象はゲーム画面上の数字を認識したいので,手書き文字と異なりフォントが固定されているので認識も簡単であると思われる.
予測が難しい状況
とはいえ認識が難しい状況はある.一つは弾が重なった時である.
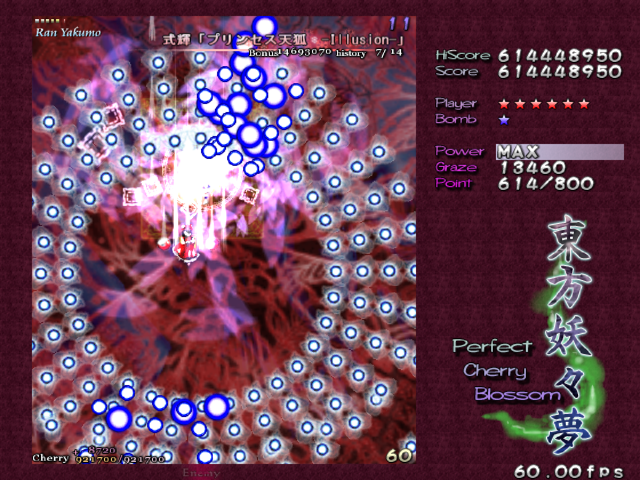 弾が重なると異なる数字として認識してしまうケースが実際にあった.
弾が重なると異なる数字として認識してしまうケースが実際にあった.
次に難しい状況は操作キャラが左下付近にいる時.
 操作キャラが左下にいると数字が薄く常時されるようになっており,認識が難しくなる.
操作キャラが左下にいると数字が薄く常時されるようになっており,認識が難しくなる.
そして一番難しいのは操作キャラが左下にいて弾が重なった時となる.
またステージが変わると背景情報も変わるため,特定のステージだけで学習しても他のステージだとうまくいかないケースも見受けられた.
どうやって予測するのか
まず左下の数字の画像を各桁毎の画像に分解する.

そして各画像に対して手作業で(!)何の数字が書かれているのか正解ラベルをつける.実際の作業時間はここが大半になる.
ちなみにだが1桁目は必ず0となるので,ここは無視する.
最終的には正解ラベルとなる関数
を求めることになる.
具体的な手順
ゲーム画面のスクリーンショットを取る
画像としてスクリーンショットを保存する作業が必要になる.以下がそのためのコードとなる.
import pygetwindow as gw import pyautogui from PIL import Image import mss import time import datetime def get_screanshot(title='東方妖々夢\u3000~ Perfect Cherry Blossom. ver 1.00b'): windows = gw.getWindowsWithTitle(title) left = windows[0].left top = windows[0].top width = windows[0].width height = windows[0].height with mss.mss() as sct: monitor = { "top": top+26, "left": left+3, "width": width-6, "height": height-29 } screenshot = sct.grab(monitor) img = Image.frombytes("RGB", screenshot.size, screenshot.bgra, "raw", "BGRX") return img.resize((640, 480)) while True: time.sleep(5) img = get_screanshot() d_ = datetime.datetime.now() d_s = d_.strftime('%Y%m%d%H%M%S') img.save(f'imgs/{d_s}.png')
さていくつか補足する.ウィンドウ名をもとにスクリーンショットの対象を選ぶのだが,そのままスクリーンショットを取るとウィンドウの周りの一部も画像として保存されてしまう.
そのため周囲の情報が含まれないように補正をかける必要がある.それが以下の部分となる.
with mss.mss() as sct: monitor = { "top": top+26, "left": left+3, "width": width-6, "height": height-29 } screenshot = sct.grab(monitor)
この部分については各自の環境で異なる可能性があるため,もし同じようなことをする方はこの部分を修正して使ってほしい.
またファイル名を桜分子の数字が含むように記述しておく.

私の場合は取得日の年月日時分秒の後に桜点情報を追記しており,桜分子が12,3450であれば_12345とつけている._は数字が記載されていない場合がそれにあたる.
例えばキャラの立ち絵で桜分子が完全に見えない時やNormalやLunatic開始時は______というファイル名となる.
各桁毎の数字に分解
import glob import os from PIL import Image import shutil from tqdm import tqdm if not os.path.isdir('train3'): os.mkdir('train3') for i in range(-1, 10): os.mkdir(f'train3/{i}') img_ids = { '_':0, '0':0, '1':0, '2':0, '3':0, '4':0, '5':0, '6':0, '7':0, '8':0, '9':0 } pix_list = [ [1, 7], [8, 14], [15, 21], [22, 28], [29, 35], [36, 42], #[43, 49] ] for p_ in tqdm(glob.glob('imgs3/*/*/*')): img = Image.open(p_) img2 = img.crop((68, 455, 117, 464)) str_num = p_.split('\\')[-1].split('-')[-1].split('.')[0] for i, (x1, x2) in enumerate(pix_list): img_ = img2.crop((x1,0,x2,9)) s_ = str_num[i] try: img_.save(f'train3/{int(s_)}/img{img_ids[s_]}.png') except: img_.save(f'train3/-1/img{img_ids[s_]}.png') img_ids[s_] +=1
スクリーンショットを保存した画像は640×480の画像サイズになっているはずなので,その画像から左下部分(今回は桜分子部分のみ)だけを抽出し,さらに数字毎に分割を行う.
保存先は各正解ラベルごとにフォルダを作成(前の項で_となっている場合は-1)し,格納していく.
今回はファイル名に桜分子を記載しているため,その文字列をもとに格納するフォルダを選択する.
学習
ここから深層学習で数字認識を行うためのモデルを作成する.今回使うのは深層学習の中でも比較的軽いResnet18を利用する.
以下のコードは上記のコードとは微妙にフォルダ構造が異なるため微調整が必要だと思うので,そこだけ注意.
import copy import glob from IPython.display import display import matplotlib.pyplot as plt import numpy as np import pandas as pd from PIL import Image from sklearn.model_selection import train_test_split import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader from torchvision.models import resnet18 from torchvision import transforms from torchvision.transforms.functional import to_tensor from tqdm import tqdm class Mydatasets(Dataset): def __init__(self, paths, transform=None): self.transform = transform self.paths = paths def __len__(self): return len(self.paths) def __getitem__(self, idx): path = self.paths[idx] label = path.split('\\')[1] if label == '-1': label = 10 else: label = int(label) img = Image.open(path) if self.transform: img = self.transform(img) return img, label transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor()] ) paths = glob.glob('train3/*/*') dataset = Mydatasets(paths, transform=transform) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) model = resnet18() model.fc = nn.Linear(model.fc.in_features, 11) model = model.to('cuda') criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) model.train() loss_list = [] best_loss = 9999 best_model_state = None for _ in tqdm(range(100)): loss_ = 0 for images, labels in dataloader: model.train() optimizer.zero_grad() images = images.to('cuda') labels = labels.to('cuda') outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() loss_ += loss.item() if best_loss > loss_: best_loss = loss_ best_model_state = copy.deepcopy(model.state_dict()) loss_list.append(loss_ / len(dataloader)) torch.save(best_model_state, 'model_gpu_ver0.03.pth')
loss関数にはCrossEntropyLossを採用し,0~9と何も書かれていない画像の11種類の分類問題として解く.
Resnet18はデフォルトだと1000分類を行うこととなるため,最終層だけは以下のように11分類ができるように調整している.
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 11)
最終的なモデルはlossが一番小さかったもの(間違えて認識したものが一番すくなかったもの)を選択できるようにしている.
学習時にはGPUを利用しているが,NVIDIA GeForce RTX4070Tiを利用して1時間30分ほどの時間がかかった.
では実際の精度はどうなっているのかを確認してみる.Lossの推移は以下のようになった.
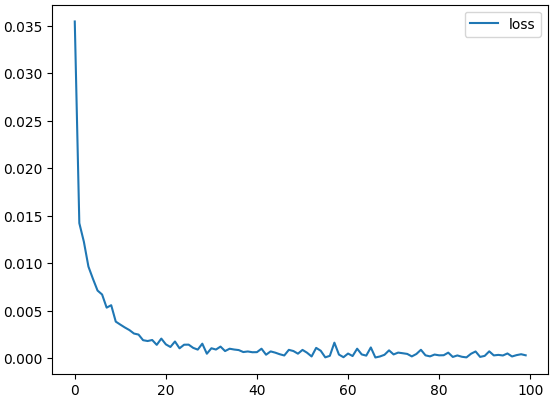
今回学習回数は100としていたが,実際には50回程度で収束しているようにも見える.
次に最終的なモデルが認識を間違えた画像を見てみる.
model.load_state_dict(best_model_state) model.eval() with torch.no_grad(): for i, (data_, label_) in enumerate(dataset): data_ = torch.unsqueeze(data_, 0).to('cuda') pred_ = model(data_) pred = torch.argmax(torch.softmax(pred_, dim=1), dim=1).cpu().numpy()[0] if label_ != pred: print(f'label:{label_} prediction:{pred} path:{paths[i]}') img_ = transforms.functional.to_pil_image(data_[0]) display(img_)

非常に見にくいが,うっすらと6という数字が書かれている.しかし予測では0となっており,間違えている.
これは操作キャラが左下に位置しており数字が薄く表示されており,かつ数字に赤い物体が重なってしまい予測が非常に難しい状況であるためであることがわかる.
今回画像は102,707枚用意したが,逆にいうと他の画像に対しては間違えていないため非常に良い精度が出ていることがわかる.
できたモデルでプレイ中に認識させてみる.
東方妖々夢を起動し,以下のコードをコンソールから実行させる.
import datetime import pygetwindow as gw from PIL import Image import mss import time import torch import torch.nn as nn from torchvision.models import resnet18 from torchvision import transforms class CherryReader: def __init__(self, device='cuda'): self.device = device self.model = resnet18() self.model.fc = nn.Linear(self.model.fc.in_features, 11) self.model = self.model.to(device) self.model.load_state_dict(torch.load('model_gpu_ver0.03.pth')) self.transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor()] ) def _get_screanshot(self, title='東方妖々夢\u3000~ Perfect Cherry Blossom. ver 1.00b'): windows = gw.getWindowsWithTitle(title) left = windows[0].left top = windows[0].top width = windows[0].width height = windows[0].height with mss.mss() as sct: monitor = { "top": top+26, "left": left+3, "width": width-6, "height": height-29 } screenshot = sct.grab(monitor) img = Image.frombytes("RGB", screenshot.size, screenshot.bgra, "raw", "BGRX") return img.resize((640, 480)) def _read_cherry_img(self, img): pix_list = [ [1, 7], [8, 14], [15, 21], [22, 28], [29, 35], [36, 42], #[43, 49] ] img_ = img.crop((68, 455, 117, 464)) img_list = [img_.crop((x1, 0, x2, 9)) for x1,x2 in pix_list] img_list = [self.transform(im_).view(1,3,64,64) for im_ in img_list] return torch.cat(img_list) def _read_cherry(self, data): self.model.eval() with torch.no_grad(): output = self.model(data.to(self.device)) #return ''.join([str(i) if i<10 else ' ' for i in torch.argmax(torch.softmax(output, dim=1), dim=1).cpu().numpy()]) return ''.join([str(i) if i<10 else '_' for i in torch.argmax(torch.softmax(output, dim=1), dim=1).cpu().numpy()]) def main(self): img = self._get_screanshot() res = self._read_cherry_img(img) return img, self._read_cherry(res) def create_data(self, t=1): while True: time.sleep(t) img, res = self.main() d_ = datetime.datetime.now().strftime('%Y%m%d%H%M%S%f') img.save(f'imgs3/{d_}-{res}.png') def predict_cherry(self, t=1): while True: time.sleep(t) _, res = self.main() res = res.replace('_', ' ') + '0' print(res) if __name__ == '__main__': cr = CherryReader() cr.predict_cherry(t=1) #cr.create_data(t=1)

GPUを使ってはいるものの,多感だと大体秒間2~3回程度の速度で認識を行ってくれている.数字の認識についても特に問題はなさそうだった.
またウィンドウの位置や大きさについても特に問題なく予測もできているが,フルスクリーンのみ未実験であるため,ここはどうなるか分からない.
まとめ
今回はResnet18を使った桜分子の認識を行った.精度は個人的には満足のいくものになってくれた.
課題,というか不可能なこととしてゲーム内の振動(二十結界や橙の晴明大紋等),ボスとの会話中のキャラ立ち絵が重なって物理的に見えない時には対応できない問題はある.
今後は万人が使えるツールとして展開できれば良いと思う.またどこをプレイしているのかの認識や,結界中かどうかの判定もできたらと思う.


