東方妖々夢のゲーム画面上の数字認識
概要
東方妖々夢のゲーム画面の左下には3つの数字がある.
この数字は主にスコアアタックで重要になるが,うまく使うと通常クリアやノーボム(以下NB)でも役に立つ.
私はこのゲームのスコアアタックを行っているのだが,ポイント毎にどの程度増えたのかを認識しつつプレイしている.
とはいえ毎回覚えているわけでもなく,できれば記録してどこがダメなのかを把握して自分の弱点部分の練習を行いたい状況は多い.
一応東方作品にはリプレイ機能を搭載しているので,リプレイファイルを保存して振り返ればデータを手動で取ることは一応可能である.
しかしこれは結構手間であり,自動記録を行うツールが欲しいと思っていたのだ.
現状そのようなツールはなく,じゃあ自分で作ってみるか,となったわけである.
東方妖々夢の左下の解説
簡単に妖々夢の左下の三つの数字について説明しておく.

まず上段について,ここが50,000に到達すると森羅結界(以下結界)が発動する.この結界がスコアアタックにおいては非常に重要になる.
次に下段右,これは下段左の数字の上限を表している.この数字は結界中と結界終了時にのみ増やすことができる.正式名称はないが,一般的には桜分母と呼ばれる.
最後に下段左,これは現在の点アイテムの最大点を表している.東方妖々夢では点アイテムを回収した場所が画面上部であるほどこの数字に近づくことになる.ここも正式名称はないが,桜分子と呼ばれる.
まとめると,特に下段の二つの数字をできるだけ高く保つ必要がある,ということになる.
そのため結界中にどれだけ伸びたのかを記録し,他プレイヤーと比べてどうなのかの調査につなげるのが目的となる.
数字認識の方針
何を使って予測するのか
今回は深層学習を使って文字認識を行う.
文字認識についてはMNIST等の手書き文字の認識を行うサンプルが多く公開されているため,似たようなことは可能と考えられる.
対象はゲーム画面上の数字を認識したいので,手書き文字と異なりフォントが固定されているので認識も簡単であると思われる.
予測が難しい状況
とはいえ認識が難しい状況はある.一つは弾が重なった時である.
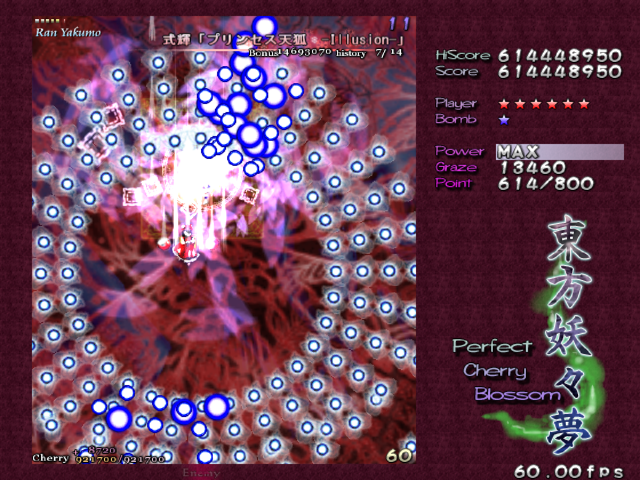 弾が重なると異なる数字として認識してしまうケースが実際にあった.
弾が重なると異なる数字として認識してしまうケースが実際にあった.
次に難しい状況は操作キャラが左下付近にいる時.
 操作キャラが左下にいると数字が薄く常時されるようになっており,認識が難しくなる.
操作キャラが左下にいると数字が薄く常時されるようになっており,認識が難しくなる.
そして一番難しいのは操作キャラが左下にいて弾が重なった時となる.
またステージが変わると背景情報も変わるため,特定のステージだけで学習しても他のステージだとうまくいかないケースも見受けられた.
どうやって予測するのか
まず左下の数字の画像を各桁毎の画像に分解する.

そして各画像に対して手作業で(!)何の数字が書かれているのか正解ラベルをつける.実際の作業時間はここが大半になる.
ちなみにだが1桁目は必ず0となるので,ここは無視する.
最終的には正解ラベルとなる関数
を求めることになる.
具体的な手順
ゲーム画面のスクリーンショットを取る
画像としてスクリーンショットを保存する作業が必要になる.以下がそのためのコードとなる.
import pygetwindow as gw import pyautogui from PIL import Image import mss import time import datetime def get_screanshot(title='東方妖々夢\u3000~ Perfect Cherry Blossom. ver 1.00b'): windows = gw.getWindowsWithTitle(title) left = windows[0].left top = windows[0].top width = windows[0].width height = windows[0].height with mss.mss() as sct: monitor = { "top": top+26, "left": left+3, "width": width-6, "height": height-29 } screenshot = sct.grab(monitor) img = Image.frombytes("RGB", screenshot.size, screenshot.bgra, "raw", "BGRX") return img.resize((640, 480)) while True: time.sleep(5) img = get_screanshot() d_ = datetime.datetime.now() d_s = d_.strftime('%Y%m%d%H%M%S') img.save(f'imgs/{d_s}.png')
さていくつか補足する.ウィンドウ名をもとにスクリーンショットの対象を選ぶのだが,そのままスクリーンショットを取るとウィンドウの周りの一部も画像として保存されてしまう.
そのため周囲の情報が含まれないように補正をかける必要がある.それが以下の部分となる.
with mss.mss() as sct: monitor = { "top": top+26, "left": left+3, "width": width-6, "height": height-29 } screenshot = sct.grab(monitor)
この部分については各自の環境で異なる可能性があるため,もし同じようなことをする方はこの部分を修正して使ってほしい.
またファイル名を桜分子の数字が含むように記述しておく.

私の場合は取得日の年月日時分秒の後に桜点情報を追記しており,桜分子が12,3450であれば_12345とつけている._は数字が記載されていない場合がそれにあたる.
例えばキャラの立ち絵で桜分子が完全に見えない時やNormalやLunatic開始時は______というファイル名となる.
各桁毎の数字に分解
import glob import os from PIL import Image import shutil from tqdm import tqdm if not os.path.isdir('train3'): os.mkdir('train3') for i in range(-1, 10): os.mkdir(f'train3/{i}') img_ids = { '_':0, '0':0, '1':0, '2':0, '3':0, '4':0, '5':0, '6':0, '7':0, '8':0, '9':0 } pix_list = [ [1, 7], [8, 14], [15, 21], [22, 28], [29, 35], [36, 42], #[43, 49] ] for p_ in tqdm(glob.glob('imgs3/*/*/*')): img = Image.open(p_) img2 = img.crop((68, 455, 117, 464)) str_num = p_.split('\\')[-1].split('-')[-1].split('.')[0] for i, (x1, x2) in enumerate(pix_list): img_ = img2.crop((x1,0,x2,9)) s_ = str_num[i] try: img_.save(f'train3/{int(s_)}/img{img_ids[s_]}.png') except: img_.save(f'train3/-1/img{img_ids[s_]}.png') img_ids[s_] +=1
スクリーンショットを保存した画像は640×480の画像サイズになっているはずなので,その画像から左下部分(今回は桜分子部分のみ)だけを抽出し,さらに数字毎に分割を行う.
保存先は各正解ラベルごとにフォルダを作成(前の項で_となっている場合は-1)し,格納していく.
今回はファイル名に桜分子を記載しているため,その文字列をもとに格納するフォルダを選択する.
学習
ここから深層学習で数字認識を行うためのモデルを作成する.今回使うのは深層学習の中でも比較的軽いResnet18を利用する.
以下のコードは上記のコードとは微妙にフォルダ構造が異なるため微調整が必要だと思うので,そこだけ注意.
import copy import glob from IPython.display import display import matplotlib.pyplot as plt import numpy as np import pandas as pd from PIL import Image from sklearn.model_selection import train_test_split import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader from torchvision.models import resnet18 from torchvision import transforms from torchvision.transforms.functional import to_tensor from tqdm import tqdm class Mydatasets(Dataset): def __init__(self, paths, transform=None): self.transform = transform self.paths = paths def __len__(self): return len(self.paths) def __getitem__(self, idx): path = self.paths[idx] label = path.split('\\')[1] if label == '-1': label = 10 else: label = int(label) img = Image.open(path) if self.transform: img = self.transform(img) return img, label transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor()] ) paths = glob.glob('train3/*/*') dataset = Mydatasets(paths, transform=transform) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) model = resnet18() model.fc = nn.Linear(model.fc.in_features, 11) model = model.to('cuda') criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) model.train() loss_list = [] best_loss = 9999 best_model_state = None for _ in tqdm(range(100)): loss_ = 0 for images, labels in dataloader: model.train() optimizer.zero_grad() images = images.to('cuda') labels = labels.to('cuda') outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() loss_ += loss.item() if best_loss > loss_: best_loss = loss_ best_model_state = copy.deepcopy(model.state_dict()) loss_list.append(loss_ / len(dataloader)) torch.save(best_model_state, 'model_gpu_ver0.03.pth')
loss関数にはCrossEntropyLossを採用し,0~9と何も書かれていない画像の11種類の分類問題として解く.
Resnet18はデフォルトだと1000分類を行うこととなるため,最終層だけは以下のように11分類ができるように調整している.
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 11)
最終的なモデルはlossが一番小さかったもの(間違えて認識したものが一番すくなかったもの)を選択できるようにしている.
学習時にはGPUを利用しているが,NVIDIA GeForce RTX4070Tiを利用して1時間30分ほどの時間がかかった.
では実際の精度はどうなっているのかを確認してみる.Lossの推移は以下のようになった.
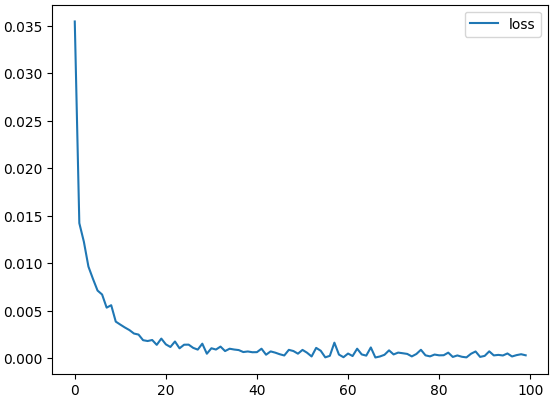
今回学習回数は100としていたが,実際には50回程度で収束しているようにも見える.
次に最終的なモデルが認識を間違えた画像を見てみる.
model.load_state_dict(best_model_state) model.eval() with torch.no_grad(): for i, (data_, label_) in enumerate(dataset): data_ = torch.unsqueeze(data_, 0).to('cuda') pred_ = model(data_) pred = torch.argmax(torch.softmax(pred_, dim=1), dim=1).cpu().numpy()[0] if label_ != pred: print(f'label:{label_} prediction:{pred} path:{paths[i]}') img_ = transforms.functional.to_pil_image(data_[0]) display(img_)

非常に見にくいが,うっすらと6という数字が書かれている.しかし予測では0となっており,間違えている.
これは操作キャラが左下に位置しており数字が薄く表示されており,かつ数字に赤い物体が重なってしまい予測が非常に難しい状況であるためであることがわかる.
今回画像は102,707枚用意したが,逆にいうと他の画像に対しては間違えていないため非常に良い精度が出ていることがわかる.
できたモデルでプレイ中に認識させてみる.
東方妖々夢を起動し,以下のコードをコンソールから実行させる.
import datetime import pygetwindow as gw from PIL import Image import mss import time import torch import torch.nn as nn from torchvision.models import resnet18 from torchvision import transforms class CherryReader: def __init__(self, device='cuda'): self.device = device self.model = resnet18() self.model.fc = nn.Linear(self.model.fc.in_features, 11) self.model = self.model.to(device) self.model.load_state_dict(torch.load('model_gpu_ver0.03.pth')) self.transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor()] ) def _get_screanshot(self, title='東方妖々夢\u3000~ Perfect Cherry Blossom. ver 1.00b'): windows = gw.getWindowsWithTitle(title) left = windows[0].left top = windows[0].top width = windows[0].width height = windows[0].height with mss.mss() as sct: monitor = { "top": top+26, "left": left+3, "width": width-6, "height": height-29 } screenshot = sct.grab(monitor) img = Image.frombytes("RGB", screenshot.size, screenshot.bgra, "raw", "BGRX") return img.resize((640, 480)) def _read_cherry_img(self, img): pix_list = [ [1, 7], [8, 14], [15, 21], [22, 28], [29, 35], [36, 42], #[43, 49] ] img_ = img.crop((68, 455, 117, 464)) img_list = [img_.crop((x1, 0, x2, 9)) for x1,x2 in pix_list] img_list = [self.transform(im_).view(1,3,64,64) for im_ in img_list] return torch.cat(img_list) def _read_cherry(self, data): self.model.eval() with torch.no_grad(): output = self.model(data.to(self.device)) #return ''.join([str(i) if i<10 else ' ' for i in torch.argmax(torch.softmax(output, dim=1), dim=1).cpu().numpy()]) return ''.join([str(i) if i<10 else '_' for i in torch.argmax(torch.softmax(output, dim=1), dim=1).cpu().numpy()]) def main(self): img = self._get_screanshot() res = self._read_cherry_img(img) return img, self._read_cherry(res) def create_data(self, t=1): while True: time.sleep(t) img, res = self.main() d_ = datetime.datetime.now().strftime('%Y%m%d%H%M%S%f') img.save(f'imgs3/{d_}-{res}.png') def predict_cherry(self, t=1): while True: time.sleep(t) _, res = self.main() res = res.replace('_', ' ') + '0' print(res) if __name__ == '__main__': cr = CherryReader() cr.predict_cherry(t=1) #cr.create_data(t=1)

GPUを使ってはいるものの,多感だと大体秒間2~3回程度の速度で認識を行ってくれている.数字の認識についても特に問題はなさそうだった.
またウィンドウの位置や大きさについても特に問題なく予測もできているが,フルスクリーンのみ未実験であるため,ここはどうなるか分からない.
まとめ
今回はResnet18を使った桜分子の認識を行った.精度は個人的には満足のいくものになってくれた.
課題,というか不可能なこととしてゲーム内の振動(二十結界や橙の晴明大紋等),ボスとの会話中のキャラ立ち絵が重なって物理的に見えない時には対応できない問題はある.
今後は万人が使えるツールとして展開できれば良いと思う.またどこをプレイしているのかの認識や,結界中かどうかの判定もできたらと思う.
初コミケ参加の個人的振り返り
概要
2025夏のコミケに初参加してきました.サークル側で.
大学院時代の友人がやってるとは聞いてて,今回お誘いの連絡があったため自分も一冊書いて出す予定でした.印刷所のミスで出せなかったけどな!
冬に今回ダメだった機械学習本を出す予定.冬までに新たに作るかはわからない.
ちなみに数学系サークルなのでエ〇は全くない,というか絵もほとんどない.
今回初参加ということで来年の夏に参加するならということでメモを残しておく.
準備に関して
飲料水関係
友人からは2Lは用意しといたほうがいいと聞いていたが,店番もやってたせいかそこまで水の消費は多くなかった(1Lくらい?).
とはいえ水分の確保は必須なので1L+現地調達くらいでいいかも?自販機やコンビニで購入はできそうだった.
今回は保冷バッグに2Lペットボトルを入れてぬるくならないように対策し,タンブラーに入れることで対応.
氷も保冷剤兼タンブラーに入れる要で買ってたが,特に使うことはなかった.ちゃんとした保冷剤があればいいかも?
暑さ対策
帽子は外に出る場合がなんだかんだあるんで必須.
ネッククーラーや冷感アームカバーも買ってたけど特に使わなかったが,購入者として動き回るならあったほうが良さそう.
自分はあまり動き回らなかったからそこまでいらなかったかも.
また扇子を持ってたので持って行ったが,団扇よりはかさばらないのでそこは良かった.
制汗スプレー,空調服はあってもよかったかもしれない.
塩分対策 タブレットで対応.かさばらなければ量は持っていけばいい.
雨対策 合羽はあった方がいいと聞いてたが,今回は雨は降らなかったので助かった.でも雨天時だったらと思うと必要と感じた.
手荷物
帰りも考えると軽装で行きたい.が,今回はちょっと多かったかも…
保冷バッグを仕切って戦利品と水系が離れるようにできればよかったかも.
当日に関して
サークル調査
初参加ということでそこまで行きたいってサークルは多くなかったけど,他を探そうとするとwebカタログ使いにくい…
日頃からXなりで目星をつけておく方がいいか.
帰りがしんどい
荷物がちょい多めになることもあり,行きの荷物が多いとちょっとしんどくなる.
特に会場を出た直後の帰りの電車は割と地獄…
湿度が高いと不快さもやばいが,一番体調がしんどかったのがココ.帰るまでがコミケなんだなと痛感.
自宅の最寄り駅~自宅を歩いたのが最大の失敗だった気がするから,タクシーで帰るべきだった…
アレックスブライト打ってみた
概要
友人が出張で近場に来た&一緒に打つ時間もあるということで,アレックスブライトを初打ちしてきました.
結果
自分は-10k,友人は+15kくらい.ちなみに羽合算確率は自分が5~6,友人は1付近.
良かったところ
5号機アレックスはそこそこ打ってたので,制御や演出法則の変化がないのは自分としては良かった.
ブライトループはBB10回中1回しか入らなかったものの,確実に500枚取れるフラグがあるのはいいと思う.もう一回続けば700枚超えで4号機レベルだし.
悪かったところ?
クラックチャンスはどう楽しむのかが4000G程度では見つけられなかった.最後のほうは白なら左フリー打ちとかやってたけど,現状微妙.中とか右でやればいいのかな?
AREX ZONEはリーチ目コレクション埋める用として割り切るならアリだけど,レア役の完全告知はちょい微妙かな?自分はあまりやらないけどBB後即止めしにくい雰囲気は強く感じた.
一応サイドLED白でブドウ・羽・鳥が左第一停止ならブドウorボーナスになるからこの辺りなら楽しめそう.中や右でリプレイ否定する形が作れても面白いかも?今後試したい.
内容としてはどうだったのか
今回は4203G回して,
羽合算 344回 1/12.2(5~6)、A155回B189回
羽羽鳥 92回 1/45.7(奇数よりで1以下)
チェリーA2 88回 1/47.76(1or2だが2の公表値よりも引けてない)
チェリーB 56回 1/75.05(6以上)
BB 10回 1/420.3(1以下)
RB 17回 1/247.24(6以上)
BB中羽羽鳥A 36回 1/4.6(奇数より)
BB中羽羽鳥B 13回 1/12.7(5以上)
BB中羽羽鳥C 0回
RB後ALEX 0回
という感じ.判別ツールにかけると1or5.
一応演者来店の日だったのでもしかしたら5あるかな?そうだとすると負けてるんでショック…
考察
後日データサイトでグラフを見ると,友人が打ってた台は高設定のようなグラフに,自分のは大きなハマり(自分で900G,後で打ってた人もおそらく同程度が1回)あってグラフが乱高下してる感じ.
となると羽の合算が悪かった友人の台を高設定と仮定し,私の打ってた台を1と仮定するのが良さそう.
であれば,羽合算はあまり当てにしないほうがいい?AB個別に見ないと推測には使えない可能性もあるのかな?
RBの当選回数は4000Gでもあまり当てにしないほうがいいかも?ただ大きなハマりが原因で負けた感あるので何とも言えないか.
友人のユニメモデータを貰ってまた自分なりに分析してみようかと思います.どうせまた打つだろうからね.
パチスロのボーナス抽選の考察
概要
とある動画でこんな話がありました.
ボーナス抽選が多数の小役の重複で抽選されている台と,5号機ジャグラーのように単独とチェリー重複のような台があった時,ボーナス確率が同じだとしてどっちがボーナスを引く回数が荒れるのか?
数学的に考察すれば結論はでると思いますが,今回はシミュレーションしてみて比較しようと思います.
ちなみに前者の方が荒れるという方の方が多数なんだとか.感覚的には重複する役をそもそも引けない場合はボーナスにつながらないし,引ける場合はボーナスのチャンスが多くなるからそっちの方があれるよね,ということだと思います.
シミュレーションをどうやるか?
私がこの手のパチスロシミュレーションをする場合,プログラム上に65536個のくじを準備して一枚一枚にはハズレとか単独ボーナスとかスイカ+ボーナスとか書いたものを準備するようにしています.
これがシミュレーションしたい機種のボーナス確率と一致するようして,後はここから1枚引くことでパチスロの1ゲームを表現しています.
出玉の計算みたいなのはこれだけだとできませんが,小役やボーナスの出現確率くらいならどれくらい荒れるのかのシミュレーションは十分できます.
ただし今回やりたいことはこれだとシミュレーションが難しいので,別の方法を行うことにします.
具体的には,ボーナス抽選を行う小役を引いたときは別途ボーナス抽選を別に行うこととします.実際のパチスロ機がどうやって抽選してるのかは私は知りませんが,今回はこの方法でやってみます.
実際の機種でシミュレーションしてみる
今回は5号機ハナビで行います.設定1ではボーナス抽選を行う小役の出現確率はチェリーBで1/243.63,一枚役A(通称コブナ)で1/1560.38,一枚役Bで1/606.81,一枚役AB同時成立役で1/1927.53,特殊リプレイで1/1560.38.チェリーBのみ5.2%でボーナス抽選を行うようになっていて,他の役は100%重複します.それ以外は重複抽選を行っておらず,しいていうならハズレを引いたときに単独ボーナスが成立する可能性があります.
先述したシミュレーション方法を行うので,65536枚のくじがある場合は5号機ハナビだと単独ボーナスが140,一枚役Aが42,Bが108,AB同時成立が34,特殊リプレイが42あります.チェリーBは269個あり,このうち5.2%でボーナス当選することになります.個数でいうと269個中14個当たりがあることになります.
この状況をコード化してみます.
とりあえず1万ゲーム回した状況を1万回やってみます.
import matplotlib.pyplot as plt import random import numpy as np machine = ['単独ボーナス' for i in range(140)] + ['一枚役A' for i in range(42)] + ['一枚役B' for i in range(108)] + ['一枚役AB' for i in range(34)] + ['特殊リプレイ' for i in range(42)] + ['チェリーB' for i in range(269)] machine += ['ハズレ' for i in range(65536-len(machine))] bonus_lottery = ['ボーナス' for i in range(14)] + ['ハズレ' for i in range(269-14)] result = [] for i in range(10000): res_ = 0 for i in range(10000): r = random.choice(machine) if r in ['単独ボーナス', '一枚役A', '一枚役B', '一枚役A', '一枚役AB', '特殊リプレイ']: res_ += 1 elif r == 'チェリーB': r2 = random.choice(bonus_lottery) if r2 == 'ボーナス': res_ += 1 result.append(res_)
このコードを実行すると,乱数に左右されますが1万ゲームで何回ボーナスを引いたかを1万回やった結果がでます.
では各何回引いたのかを可視化してます.
plt.hist(result)

乱数次第,実際に打つ場合は引き次第でボーナス合計30回程度もあれば80回の場合もありますね.
次に単独ボーナスが1/172.46で成立している状況での抽選結果を見てみます.この確率はハナビのボーナス合算と同じになります.
この確率だと65536中380当たりがあることになります.
machine2 = ['ボーナス' for i in range(380)] + ['ハズレ' for i in range(65536-380)] result2 = [] for i in range(10000): res_ = 0 for i in range(10000): r = random.choice(machine2) if r == 'ボーナス': res_ += 1 result2.append(res_) plt.hist(result2)

グラフを見ただけだとよくわからないので,どれくらい荒れるのかの指標として分散で見てみます.大きい方が荒い,ということになります.
np.var(result) #今回は56.23921856 np.var(result2) #今回は56.033629749999996
というわけで分散の値だとほぼ変わらず.若干多数の役で抽選する場合の方が若干荒いんですが,ここは乱数次第で逆転することもあるのでほぼ同等とみていいと思います.
1万ゲームじゃなくてもっと少ないゲーム数なら?
1万ゲームだと1日中パチスロ打ってて達成できるゲーム数くらいなので,もう少し短めの3000ゲームの場合で見てみます.
machine = ['単独ボーナス' for i in range(140)] + ['一枚役A' for i in range(42)] + ['一枚役B' for i in range(108)] + ['一枚役AB' for i in range(34)] + ['特殊リプレイ' for i in range(42)] + ['チェリーB' for i in range(269)] machine += ['ハズレ' for i in range(65536-len(machine))] bonus_lottery = ['ボーナス' for i in range(14)] + ['ハズレ' for i in range(269-14)] result = [] for i in range(10000): res_ = 0 for i in range(3000): r = random.choice(machine) if r in ['単独ボーナス', '一枚役A', '一枚役B', '一枚役A', '一枚役AB', '特殊リプレイ']: res_ += 1 elif r == 'チェリーB': r2 = random.choice(bonus_lottery) if r2 == 'ボーナス': res_ += 1 result.append(res_) machine2 = ['ボーナス' for i in range(380)] + ['ハズレ' for i in range(65536-380)] result2 = [] for i in range(10000): res_ = 0 for i in range(3000): r = random.choice(machine2) if r == 'ボーナス': res_ += 1 result2.append(res_) np.var(result) np.var(result2)
実行した結果は以下のようにこちらもほぼ差がなく,むしろ単独ボーナスのみで抽選しているほうが荒めという判定になっています.

結論
本当は統計的に判断すべきでしょうが,今回のシミュレーションだとおそらく両者に差はないという結論になると思います.
ただし実際のパチスロと抽選方法が異なる可能性があるのと,できるだけ荒れるようにアルゴリズムを工夫するとも聞いたことがあるので実機でやっている場合とは異なる可能性はあります.
数学的に考えても多分荒さに差はでないと思います.
副業レポ
副業概要
※詳細は秘密保持契約を結んでいるため書けないし,答えられません
- 業務内容:将来予測
- 業務環境:自宅で自宅PCで使用
- 期間:1か月
- 業務時間:基本土日祝日の3~5時間ほど
- 報酬:本業の給料1か月分と同等
- 依頼主:友人の上司
- 納品物:予測結果と予測に使ったアルゴリズム概要
どんな感じだったのかをもう少し
きっかけは友人から副業しないか?というお誘いがあったからだった.
友人の職場で時系列予測をやらないといけなくなったのだが,データ分析系のスキルを持った人がいないとのことで,できないかと声をかけてもらったのだ.
じゃあやってみましょうということで,契約書等を書いて,先方と打ち合わせをして,ようやくデータを受け取ることができた.
とりあえず手法をいくつか試して,これでやろうと決めたら後は前処理の検討をしては分析結果を見て,また前処理検討に戻るの繰り返し.
最後に予測結果と技術的な部分のまとめを提出,いただいたデータは削除で終了という感じだった.
本業との兼ね合い
副業に興味あるって人だとここは気になるところだと思う.
一応,弊社の場合は副業はOKだが申請が必要だった.誰を相手に,どれくらいの期間で,何をやるのかを届け出て,許可をもらう必要があった.
許可が下りるのがギリギリになったけど,ここは何とか許してもらえた.
(正直,秘密でやってもバレへんやろ…とは思ったが…)
基本的には本業を優先,土日祝日のみ副業をするということで,ワークライフバランスにも気を使ってやるよということでお許しが出たけど,結局平日の仕事終わりに副業してたこともあったのは会社にはナイショ.
副業やろうとしている方は自身が勤めている会社ではどうなのかというのはチェックしといたほうがいいかと.(会社ともめないようにしときたいしね)
(youtubeやtwitch配信で収益が発生すると届け出ないといけなさそうな雰囲気だったしなぁ…そんな人気ないだろって?そこは言わない方向で何卒)
感想
友人とやり取りしつつ進めることができたのでストレスはほとんどなかった.
むしろデータを頂く以上,自宅でできないかもと思っていたが,そこは友人が頑張ってくれたようだ.ありがたや.
分析に関しては,生データを触ることができたから確実に経験値は得られたと思う.前処理をデータの特性に沿って考えるのって大変.
ただしデータ量に対して検討する時間が短かったのが痛かった.
データ分析に関しては素人を相手にすることになっていたため,向こうの期待値の下を行ってるんじゃないかとひやひやものだったし,
技術的なことを(統計や機械学習の用語をできるだけ使わずに)説明してもなかなか理解してもらえなかったのもつらかった.
最後の方は基本土日祝日だけと思っていたけど,結局時間が足りなくて仕事終わったら副業してたしで腰をやってしまったし…
- 酷いときは座ってても辛い,立ってても辛い,寝てても辛いし,便座に腰掛けるだけでも一苦労なレベル
- ただしこれは副業があったからというより,日頃の運動不足の方が主原因
結局,土日祝日では休んだ気になれず,また趣味にかけられる時間が激減したのもあって,月曜日が本当につらかった…
とはいえ本業のお給料分は頂けることになったから,そこは良しとしよう.お金で大抵のことは我慢できるのである.
そして肉体労働系の副業やったら死んじゃうなって思いました.
2023年を振り返る~パチスロ編
今年も終わるということで
私個人の感想をつらつらと.
今年はスマスロで4号機北斗の拳のリメイク機がホールに導入されて大きな話題になった年でした.
またスマスロでなくても一撃性の高いゲーム性の機種が多く導入され,ホールに行くとやれあの機種が万枚だのコンプリート機能達成だのと一撃性が強調されているようなイメージが強い年でもありました.
私個人はAT機はあまり打たないので北斗の拳や戦国乙女等については語れることは皆無なんですが,某所での良台オブザイヤーでは上記の2機種がランクインしていましたし他も大体AT機でした.
私はAタイプ系が好きなんだけど,そんなに面白いのかなーと気になって年末を過ごしています.
では今年導入された台で私が打った台について記憶を頼りに感想を書いてみようかと思います.
モンスターハンターワールド:アイスボーン
5号機の名機と評判の月下雷鳴を踏襲した機種ということで1回だけ打ってみました.まあ月下雷鳴も4~5回くらいしか打ってないですけど.
ATについては月下雷鳴の時も思いましたが面白かった記憶があります.強レア役ありきという感じになってなさそうな印象だったけど,解析見たらまた違う感想になるかも…
ただ通常時がきつく,リプ連しないと永遠にハマるんじゃないかと錯覚するくらい.
コードギアス 反逆のルルーシュ3 C.C.&Kallen ver.
前作のCCverはそこそこ打ってたので期待して友人と一緒に1回打ちました.
ゲーム性はCCverそのままの打感だったので慣れ親しんだ感じだったかな.CC揃いが押し順リプで隠れたりするっていうのも似た感じ.
ただリーチ目はちょっと微妙な感じかなーという印象でした.まあそういう台じゃない気もするけど.
もう数回は打ちたかったんだけどあまり導入数多くないのが辛い…
傷物語-始マリノ刻-
5号機の化物語の後継機みたいな話を聞いたので1回打ちました.
まあゲーム性は似てるかな…という感じに一瞬見えましたが,なんか違うなとなった記憶があります.
また,やはりというべきか5号機の倍倍チャンスほどの凄まじさは感じなかった.これはしかたないとは思う.
ただ勝てる気がしなかった,というのが一番残っている印象かな.降臨ノ儀で爆乗せできればまた印象が変わるかも.
とはいえ平打ちは無理かな.
ファミスタ回胴版!!
ディスクアップ,いやマッピーというべきか,そういうゲーム性ということで1回打ちました.
ただ初打ちでとんでもないハマりを喰らったんで安定性はディスクアップとかマッピーとかみたいな感じで,機械割102%以上だからって安定するわけじゃないってのはそうだなと.
これも打ち込みたかったんだけどまあまあ空いてない.導入数も少ないしね.
ひぐらしのなく頃に業
5号機で一番打ち込んだ機種はひぐらしのなく頃に祭なんで,似たゲーム性だしひぐらし祭2とは別に打つことにはなるだろうから2回ほど打ちました.
打感はひぐらし祭2とは似た感じだし,ビタ押し難易度も理不尽にハマるところも似てるので違和感はない.
ただ同色BBの確率がものすごく低いということと,変に特化ゾーンや無限を付けたことで割が持っていかれててきついのは業だなという感じ.
あとシステム的にATの連荘は祭2よりもさらにしにくいといった印象.
今のところ負けてるけどもうちょい打ち込みたい機種.
魔法少女まどか☆マギカ [前編]始まりの物語/[後編]永遠の物語f-フォルテ-
長い…まどマギシリーズはすべて打ってるので嫌な予感はしつつも1回打ってみました.
まあ,うん,嫌な予感ってのは当たりますね…
1回で複数回分削れたり,一部で体力持ち越しができたりするとはいえ5戦突破形式はさすがに無理.そしてこれがゾーンほぼ無しで小役やCZで引いてくるボーナス経由じゃないと望めない.
つまり初あたりまで時間がかかり投資が嵩む.
肝心のATはというと,杏子がロング継続してくれるなら出るっていうのはわかるけど獲得できないしすぐいなくなる印象.上位ATにいれればわからないけど,そもそも引ける気がしないし.
そんで某ライターさんが言っててなるほどと思ったのは,2択ベルの存在.これがストレスの要因になるのは当然としても,押し順次第では2確でベル外れがでちゃうんですよね.ドキドキ感も取り上げるのはさすがにないわ.
残念ながらク〇台オブザイヤー候補と言われてもわるよ,としか言えない.
少なくとも平打ちはできない.
というわけで
以上が打った機種なんだけど,Aタイプ好きならエウレカとクランキーはどうしたと思われるだろう.導入数が少ないのと人気度のせいか座れてないのじゃ…この2機種とマジハロ8はなるはやで打ちたい.
Aタイプ系は6号機の規則上不遇な立場にあって大きく勝てる機種ではないかもしれないが,良い台がでることを祈っている私みたいな人もいるのでメーカーには頑張ってもらいたいなーと.
今年はタコ負けしてるので来年は良い感じになるといいな.良いお年を.
WSL上のDocker上で動いてるjupyterにアクセスしたい
概要
以下のページでWSL上にDockerの環境を立ち上げた.
これだけでもいろいろできるのだが,何かの開発をしようとすると結構面倒.
そこでとりあえずDocker image内でjupyterを立ち上げて,そこにWindowsからアクセスする方法をメモしておく.
Docker imageの作成
少し面倒だが,以下のような内容のDockerfileファイルをWSL上に作成する.
FROM nvidia/cuda:11.8.0-base-ubuntu22.04 RUN apt update RUN apt install python3.10 -y RUN apt install python3-pip -y RUN pip install jupyterlab
FROMは元となるDocker image,以降は追加で処理するコマンドをRUNで指定する.
内容としては、python3.10とpython3-pipをインストールして,jupyterlabをインストールする.
そしてこのDockerfileがある場所で以下を使ってビルド作業を行う.
docker build -t jupyter .
これでDocker imagesを実行してもらうと,jupyterというコンテナができている.
Docker runの実行で注意すること
必要なのはホスト側とコンテナ側のポート接続が必要になる.こうしないとホスト側でそのポートを認識できなくなる.実行例は以下.
docker container run -it --rm --gpus all --publish 18888:8888 jupyter
色々とオプションを付けてるが,ここで重要なのは--publish 18888:8888で,ホストの18888ポートとコンテナの8888ポートを接続することになる.
jupyter lab立ち上げ時に注意すること
後はコンテナが立ち上がったらjupyterlabを立ち上げるだけなのだが,ここでも注意点がある.
以下が大丈夫なコマンド.
jupyter lab --ip=0.0.0.0 --allow-root
--allow-rootは無いとつけないとエラーが起きる.
--ip=0.0.0.0は無いとアクセスができない.原因はよくわからない.
とりあえずこれでDocker上で実行しているjupyterにアクセスできるようになる.
もっと簡単にしたい
あれこれと実行時に指定していくのは結構面倒なので,それを簡略化する方法を記載する.
コンテナに入った後にjupyter labを立ち上げる部分を省略する
Dockerfilesを以下のように修正する.
FROM nvidia/cuda:11.8.0-base-ubuntu22.04 RUN apt update RUN apt install python3.10 -y RUN apt install python3-pip -y RUN pip install jupyterlab RUN cd mnt RUN mkdir host_src CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root"]
RUN cd mnt とRUN mkdir host_srcは別のところで使うので一応記載している部分.
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root"]はこのコマンドをコンテナ立ち上げ時に実行する命令文になっている.
これでコンテナ立ち上げ時に毎回jupyterlabを手動で実行する必要がなくなる.
docker-composeの利用
後はやりたいこととして - ホストとコンテナのport接続 - ついでにホスト側のディレクトリをコンテナ側でマウントしてソースコードを読み込めるようにする
この2点を自動化することになる.
これらを行うのにdocker-compose.ymlを利用する.
以下のページを参考にdocker-compose.ymlを作成してみた.
version: '2.21'
services:
jupyter:
container_name: jupyter
build:
context: .
ports:
- '18888:8888'
volumes:
- type: bind
source: /home/lua/src
target: /mnt/host_src
各箇所の解説は上のページを参照してもらいたい.
ともかくこれで開発は少し楽ができることが分かった.docker-compose.ymlはGPUの利用宣言なんかもできて便利.
最後に
VSCodeを利用するともっと楽できるかもしれないとのことなので,今度はそっちについても調べてみようと思う.